



Stammering Disease Prediction using Audio Dataset in Python Projects
Stammering Disease Prediction using Audio Dataset in Python Projects

Stammering Disease Prediction using Audio Dataset in Python Projects
Abstract
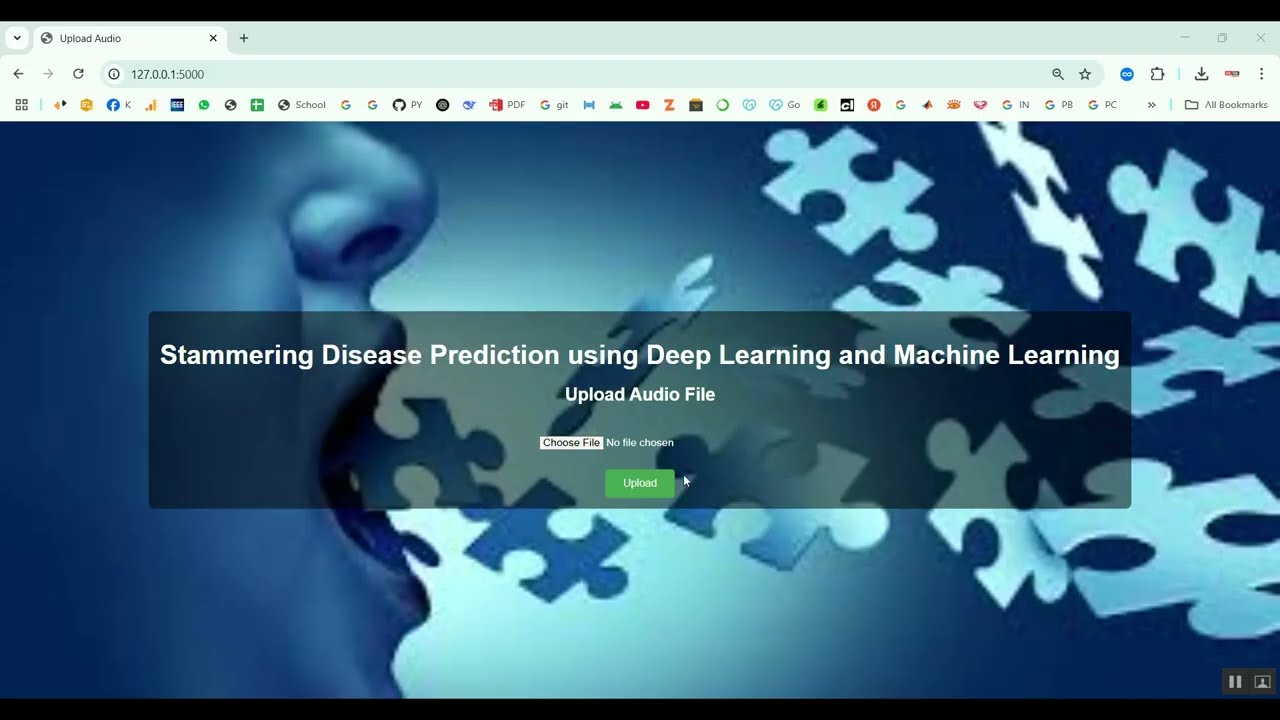
Stammering, also known as stuttering, is a speech disorder that affects communication and social interaction. Early detection and monitoring of stammering are essential for effective therapy and intervention. The project Stammering Disease Prediction using Audio Dataset in Python Projects focuses on developing an intelligent system that analyzes speech audio recordings to detect and predict stammering patterns using machine learning and deep learning techniques. Python is chosen as the development platform because of its robust libraries for audio processing, feature extraction, and machine learning, including Librosa, PyAudio, NumPy, Pandas, Scikit-learn, TensorFlow, and Keras. The system preprocesses audio data, extracts relevant features such as MFCCs, pitch, and energy, and applies predictive models to classify speech as stammered or normal. This approach supports early diagnosis, personalized therapy, and improved speech rehabilitation.
Existing System
Existing methods for stammering detection primarily rely on manual assessment by speech therapists using observation and structured speech tests. These approaches are time-consuming, subjective, and often inconsistent between different evaluators. Some automated speech analysis tools exist, but they typically use basic audio features or simple statistical methods that fail to capture complex stammering patterns, interruptions, or repetitions. Traditional systems often lack scalability, real-time prediction capability, and integration with intelligent learning models, limiting their effectiveness in large-scale or remote therapy settings.
Proposed System
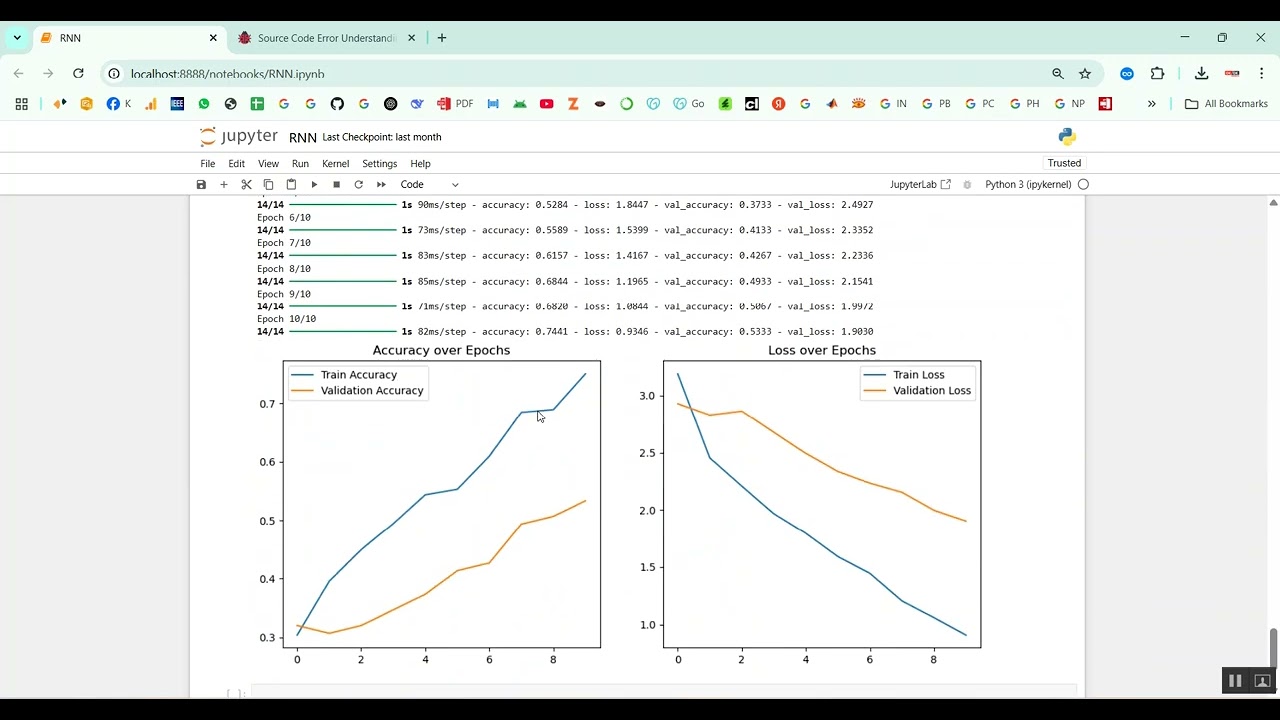
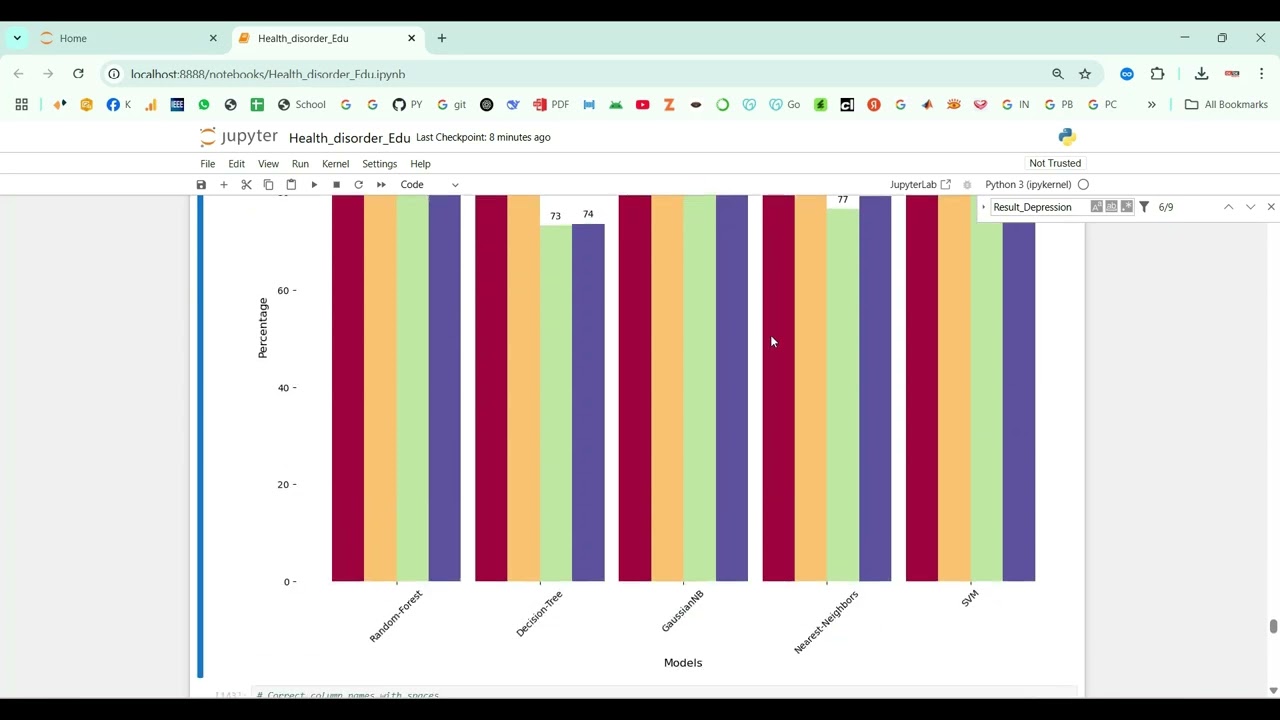
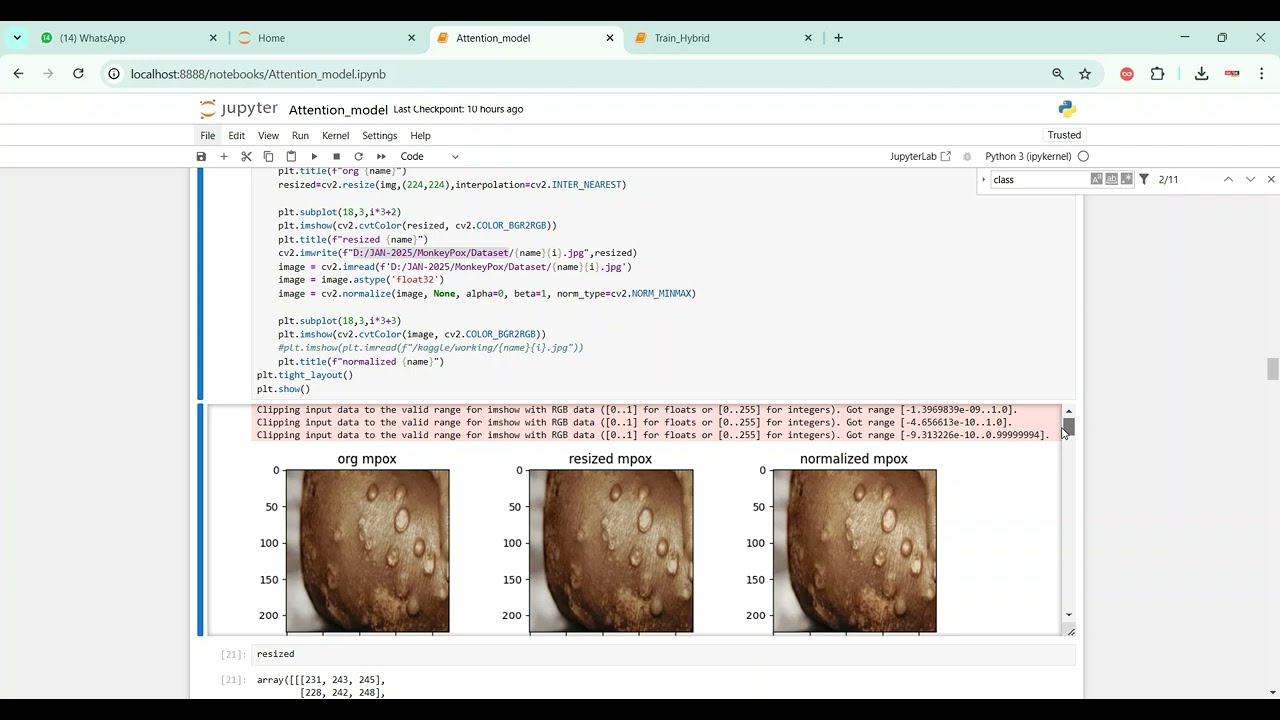
The proposed system introduces a Python-based framework for stammering detection using audio datasets and machine learning techniques. Speech recordings are preprocessed to remove background noise, normalize volume, and segment audio into frames. Feature extraction methods such as Mel-Frequency Cepstral Coefficients (MFCCs), chroma features, spectral contrast, pitch, and energy are applied to capture key speech characteristics. Machine learning models like Random Forest, Support Vector Machines (SVM), Gradient Boosting, or deep learning architectures such as CNN and LSTM are trained to classify speech as stammered or normal. The system’s performance is evaluated using metrics such as accuracy, precision, recall, F1-score, and confusion matrices. By combining advanced audio feature analysis with predictive modeling, the system provides an automated, scalable, and reliable solution for stammering disease prediction, enabling early intervention and enhancing speech therapy outcomes.
What's Your Reaction
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Angry
0
Angry
0
 Sad
0
Sad
0
 Wow
0
Wow
0