



Voice Disorder Prediction using Audio Dataset in Python Projects
Voice Disorder Prediction using Audio Dataset in Python Projects

Voice Disorder Prediction using Audio Dataset in Python Projects
Abstract
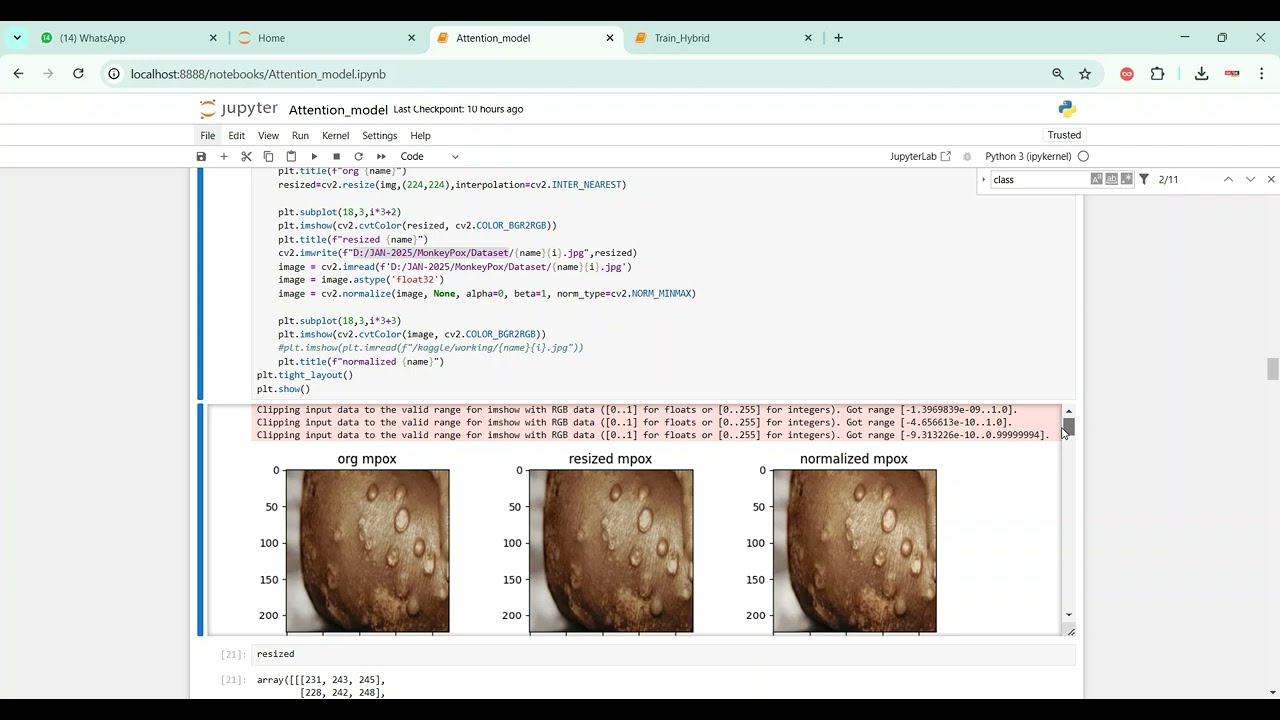
Voice disorders, including conditions like dysphonia, vocal nodules, and stuttering, can significantly impact communication and quality of life. The project Voice Disorder Prediction using Audio Dataset in Python Projects focuses on developing an intelligent system that predicts voice disorders by analyzing speech audio recordings using machine learning and deep learning techniques. Python is chosen as the development platform due to its extensive libraries for audio processing, feature extraction, and modeling, including Librosa, PyAudio, NumPy, Pandas, Scikit-learn, TensorFlow, and Keras. The system preprocesses audio signals, extracts relevant features such as Mel-Frequency Cepstral Coefficients (MFCCs), pitch, jitter, shimmer, and energy, and applies predictive models to classify normal and disordered voices. This approach enables early detection, personalized therapy, and improved patient care.
Existing System
Existing methods for diagnosing voice disorders primarily rely on clinical evaluation by speech-language pathologists, using subjective assessment, perceptual analysis, and specialized equipment. While effective, these approaches are time-consuming, labor-intensive, and prone to inter-observer variability. Some automated systems use basic signal processing techniques or simple machine learning models, but they often fail to capture complex temporal and spectral patterns in speech, limiting accuracy and generalization. Consequently, current methods may not provide scalable or real-time solutions for early diagnosis and continuous monitoring.
Proposed System
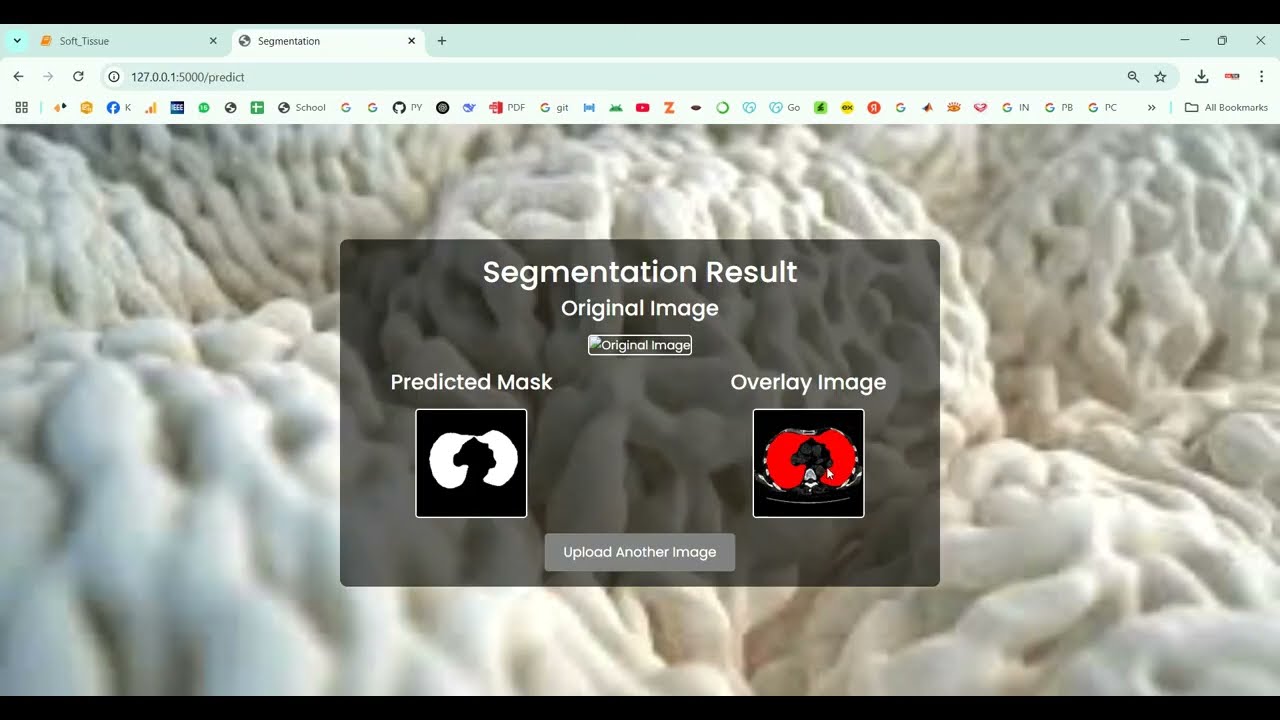
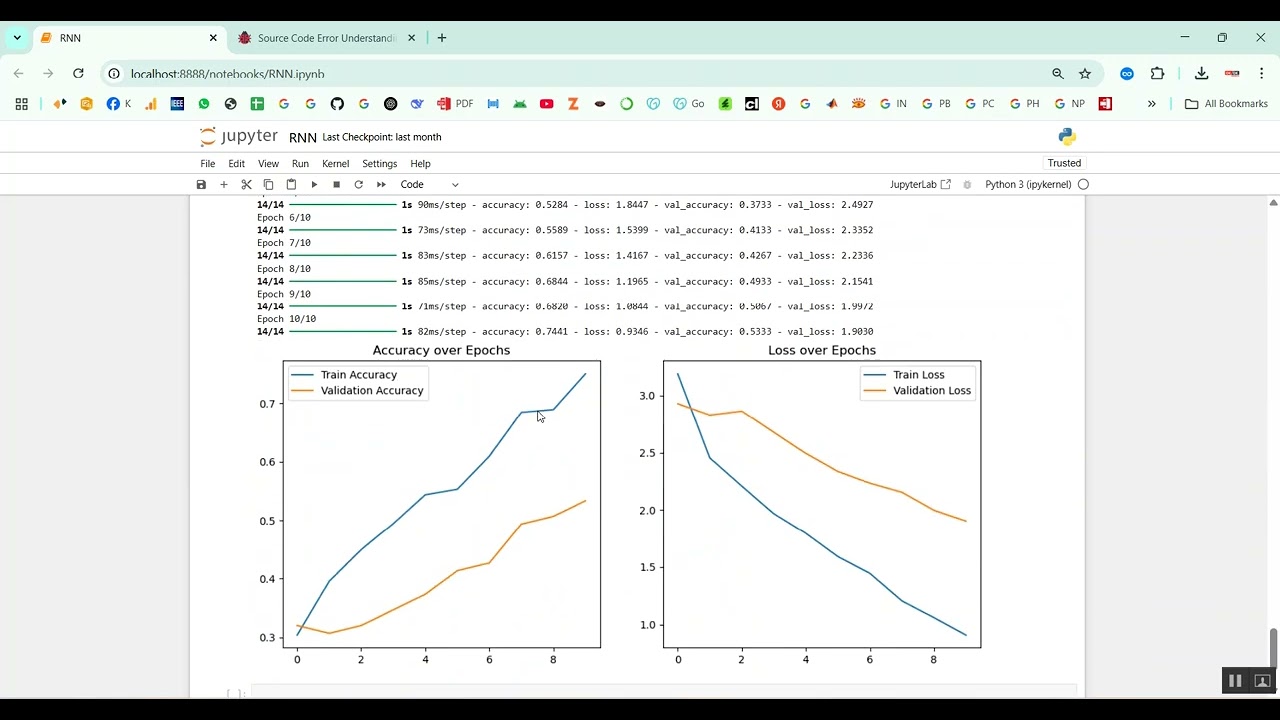
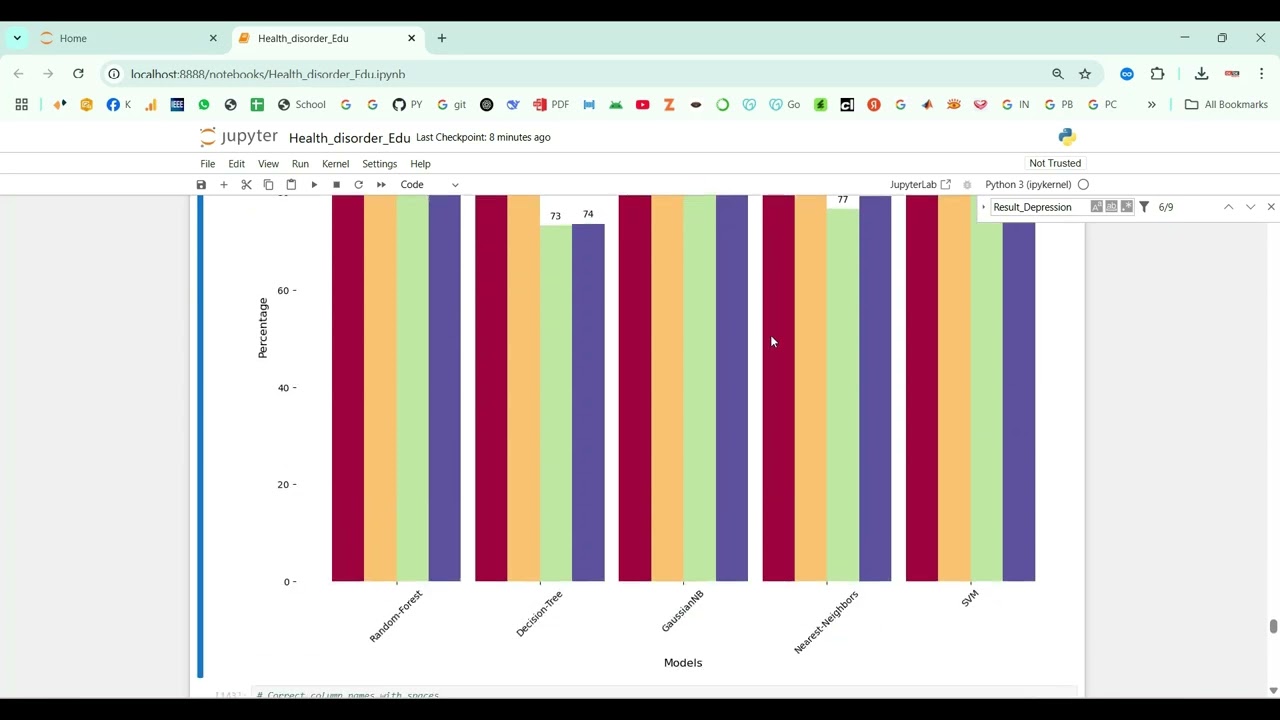
The proposed system introduces a Python-based framework for voice disorder prediction using audio datasets and machine learning techniques. Speech recordings are preprocessed to remove noise, normalize amplitude, and segment audio into relevant frames. Feature extraction includes MFCCs, chroma features, spectral contrast, pitch, jitter, shimmer, and energy to capture detailed voice characteristics. Machine learning models such as Random Forest, Support Vector Machines (SVM), Gradient Boosting, or deep learning architectures like CNN, LSTM, or hybrid CNN-LSTM are trained to classify normal and disordered voices. Model performance is evaluated using metrics such as accuracy, precision, recall, F1-score, and confusion matrices. By integrating advanced audio analysis with predictive modeling, the system provides an automated, scalable, and reliable solution for detecting voice disorders, supporting early intervention, therapy planning, and continuous patient monitoring
What's Your Reaction
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Angry
0
Angry
0
 Sad
0
Sad
0
 Wow
0
Wow
0