



Safe and Unsafe Text Classification in Python Projects
Safe and Unsafe Text Classification in Python Projects

Safe and Unsafe Text Classification in Python Projects
Abstract
With the exponential growth of online content, distinguishing between safe and unsafe text has become crucial to protect users from harmful, offensive, or misleading information. The project Safe and Unsafe Text Classification in Python Projects focuses on developing an intelligent system that classifies textual data into safe or unsafe categories using machine learning and natural language processing (NLP) techniques. Python is chosen as the development platform due to its extensive libraries for text processing, feature extraction, and machine learning, including NLTK, SpaCy, Pandas, Scikit-learn, TensorFlow, and Keras. The system preprocesses textual data, extracts features such as word embeddings, sentiment scores, and n-grams, and applies classification models to automatically detect unsafe content. This approach enhances content moderation, improves user safety, and supports automated monitoring of online platforms.
Existing System
Existing text moderation systems primarily rely on keyword-based filtering, manual review, or basic rule-based algorithms. While these methods can detect explicit offensive content, they often fail to identify subtle, context-dependent unsafe messages, sarcasm, or newly emerging harmful terms. Manual moderation is labor-intensive, slow, and inconsistent, whereas traditional machine learning approaches using bag-of-words or TF-IDF features may struggle with semantic understanding of text. Consequently, existing systems are limited in accuracy, scalability, and adaptability to the dynamic nature of online communication.
Proposed System
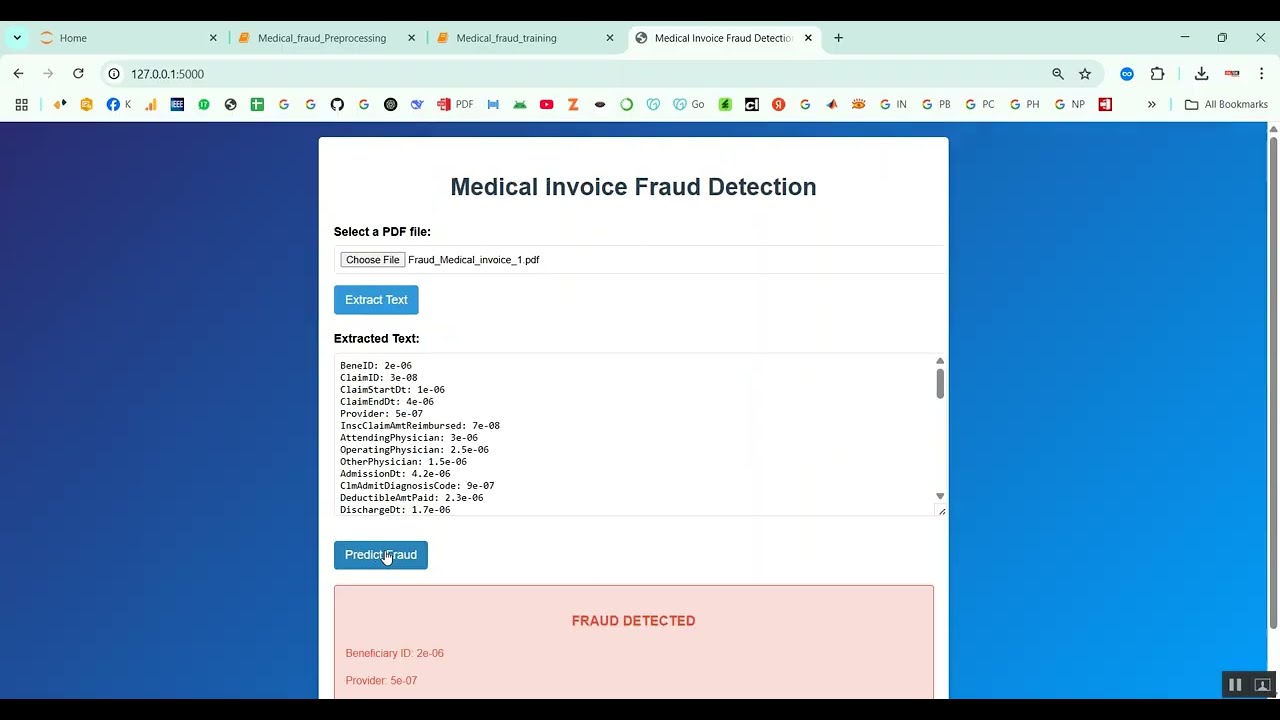
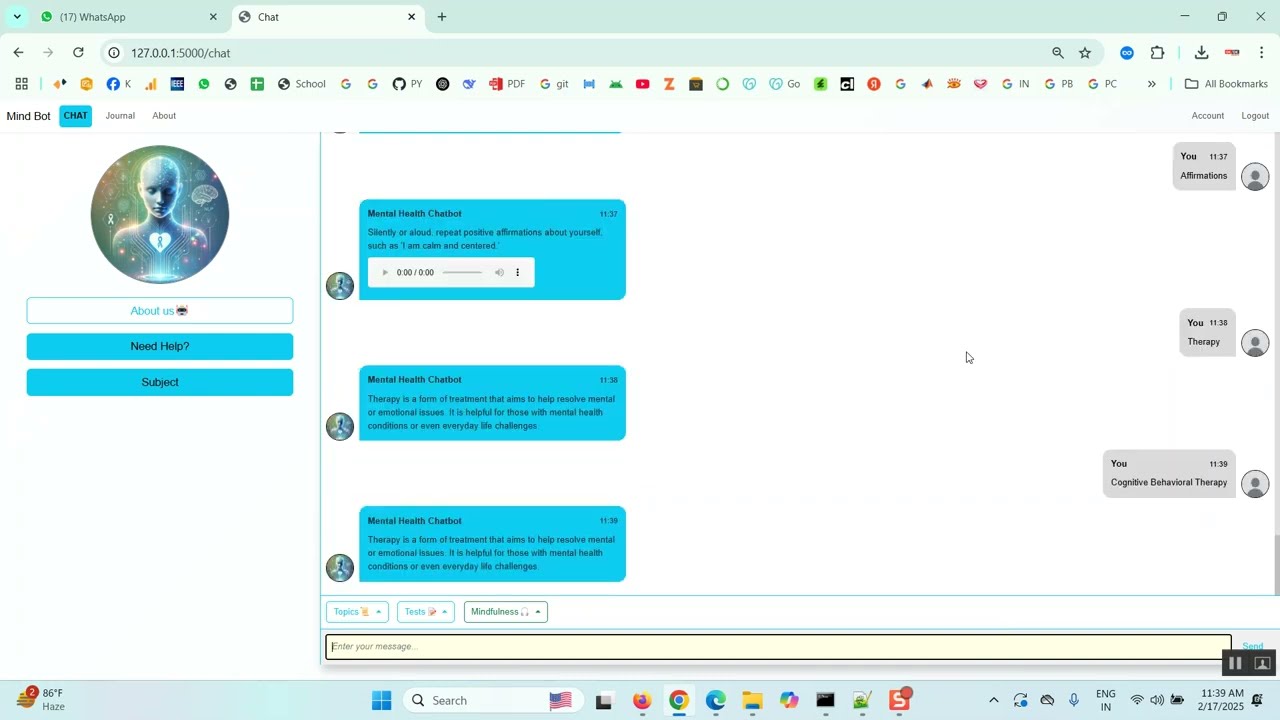
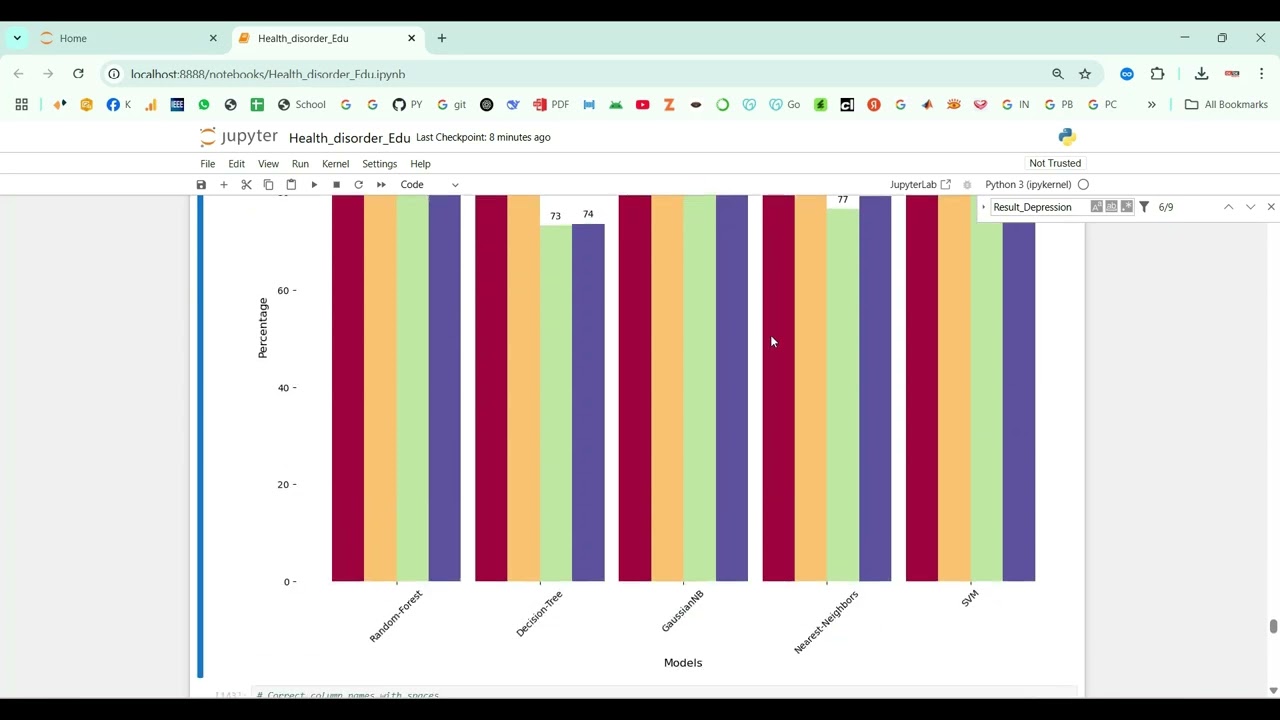
The proposed system introduces a Python-based framework for safe and unsafe text classification using NLP and machine learning. Text data is preprocessed through tokenization, lemmatization, stop-word removal, and vectorization techniques such as TF-IDF, Word2Vec, or transformer-based embeddings like BERT. Machine learning models such as Logistic Regression, Random Forest, Support Vector Machines (SVM), or deep learning models like LSTM and CNN are trained to classify text as safe or unsafe. The system’s performance is evaluated using metrics such as accuracy, precision, recall, F1-score, and confusion matrices. By combining advanced NLP techniques with machine learning classification, the system provides an automated, scalable, and accurate solution for moderating textual content, ensuring safer online communication and reducing exposure to harmful information.
What's Your Reaction
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Angry
0
Angry
0
 Sad
0
Sad
0
 Wow
0
Wow
0